
Mysql基础

Mysql基础
ActingMySQL基础篇学习
基础
访问数据库
- 属性 c 常规 包含目录 server include
- 链接器 常规 附加库目录 server lib
- 输入 依赖库 libmysql/lib
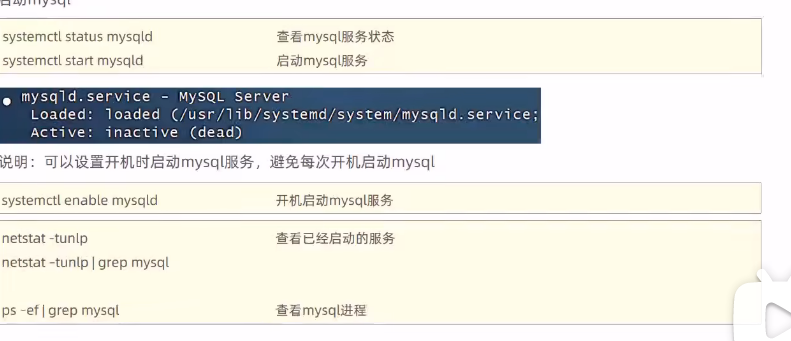
命令行操作数据库
mysql -u root -p
要先net start mysql80启动数据库服务器
MYSQL数据类型
tinyint 小整数值
smallint 大整数数值
float 单精度浮点数值
double 双精度浮点数值
char 定长字符串
varchar 变长字符串
tinytext 短文本字符串
data 日期值 YYYY-MM-DD
time 时间值或持续时间值 HH:MM:SS
year 年份值 YYYY
DDL 数据定义语言
数据库操作
查询所有数据库
SHOW DATABASES;查看当前数据库
SELECT DATABASE();创建数据库
CREATE DATABASE [IF EXISTIS]数据库名 [DEFAULT CHARSET 字符集] ;删除数据库
DROP DATABASE[IF EXISTS] 数据库名;切换数据库
USE 数据库名;查询当前数据库所有表
SHOW TABLES;
表操作
查询表结构
DESC 表名;查询创建表语句
SHOW CREATE TABLE 表名;创建表
CREATE TABLE 表名(字段 字段类型 [COMMENT 注释])[COMMENT 注释];删除表
DROP TABLE 表名;删除表内容
TRUNCATE ;修改表名 ALTER TABLE 表名 RENAME TO 新表名
字段操作
修改字段
ALTER TABLE 表名 ADD 字段名 类型(长度)[COMMENT 注释];修改字段数据类型
ALTER TABLE 表名 MODIFY 字段名 新数据类型(长度);修改数据类型和字段名称
ALTER TABLE 表明 CHANGE 旧字段名 新字段名 新类型(长度)[COMMENT 注释];删除字段
ALTER TABLE 表名 DROP 字段名;
DML 数据操作语言
添加数据 INSERT
INSERT INTO 表名(字段)VALUES(值);
修改数据 UPDATA
UPDATA 表名 SET 字段名=值 [WHERE 条件];
删除数据 DELETE
DELETE FROM 表名 WHERE 条件;
DQL 数据查询语言
SELECT 字段列表
FROM 表名列表
WHERE 条件列表
in 在其中之一
not like
%表示任何字符出现任意次数
_表示单个字符
[]表示一个字符集
GROUP BY 分组字段列表
HAVING 分组后条件列表
ORDER BY 排序字段列表
字段 默认升序 加 DESC 是降序
between and 前闭后闭
LIMIT 分页参数
- limit 起始索引 每页展示记录数
DISTINCT 数据去重
多表查询
一对多
部门 – 员工
多的一边建立外键,指向另一方的主键
多对多
- 学生 – 课程
- 中间表,至少两个外键分别关联两个主键
一对一
- 用户 用户详情
- 任意一方加入外键 设置外键为唯一约束 UNIQUE
笛卡尔查询
- 两张表所有组合情况
- 消除 WHERE 表名.字段 = 表名.字段
内连接 相当于查询A,B交集部分数据
- 隐式内连接
- SELECT 字段列表 FROM 表1,表2 WHERE;
- 显式内连接·
- SELECT 字段列表 FROM 表1【INNER】JOIN 表2 ON 连接条件
- 隐式内连接
外连接
- 左外连接
- SELECT 字段列表 FROM 表1 LEFT【OUTER】JOIN 表2 ON 条件
- 右外连接
- SELECT 字段列表 FROM 表1 RIGHT 【OUTER】JOIN 表2 ON条件
- 左外连接
自连接
- 当前表与自身连接查询 必须使用表别名
- SELECT 字段列表 FROM 表1 别名A JOIN 表1 别名B ON 条件
DCL 数据库权限
管理用户
- 查询用户
- USE mysql;
- SELECT *FROM user;
- 创建用户
- CREATE USER 用户名@主机名 IDENTIFIED BY密码;
- 修改用户密码
- ALTER USER 用户名@主机名 INENTIFIED 原密码 BY 新密码;
- 删除用户
- DROP USER 用户名@主机名;
- 任意主机名 %
约束
- 主键 PRIMARY KEY
- 自动增长 AUTO_INCREMENT
- 不为空 NOT NULL
- 唯一 UNIQUE
- 默认为1 DEFAULT
外键约束
ALTER TABLE 表名 ADD CONSITRINT 外键名称 FOREIGN KEY (外键字段名)REFERENCES 主表(主表列名)
函数
字符串函数

字符串截取 substring(字符串,起始位置,截取字符数)
字符串拼接 concat (字符串1,字符串2……)
字母大写 upper(字符串)
DATE_FORMAT(NOW(), ‘%d/%m/%Y’) AS formatted_date;
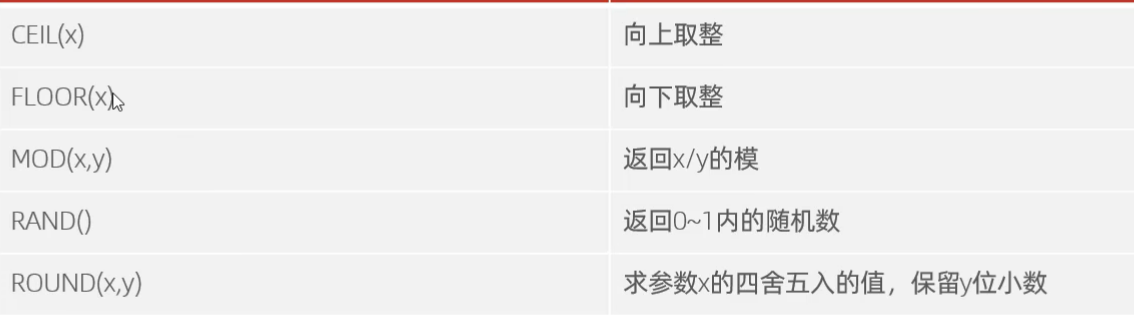
数值函数
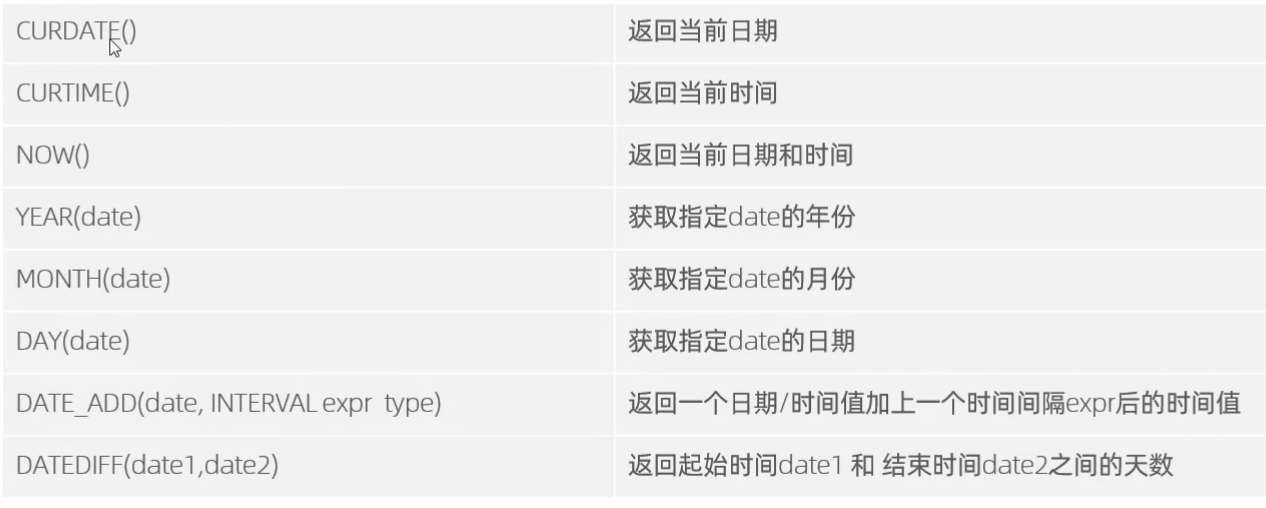
日期函数
流程函数

进阶篇学习
存储引擎
体系结构
- 连接层
- 服务层
- 引擎层
- 存储层
存储引擎 表类型
查看引擎 查看建表语句
指定存储引擎 ENGINE
SHOW engins
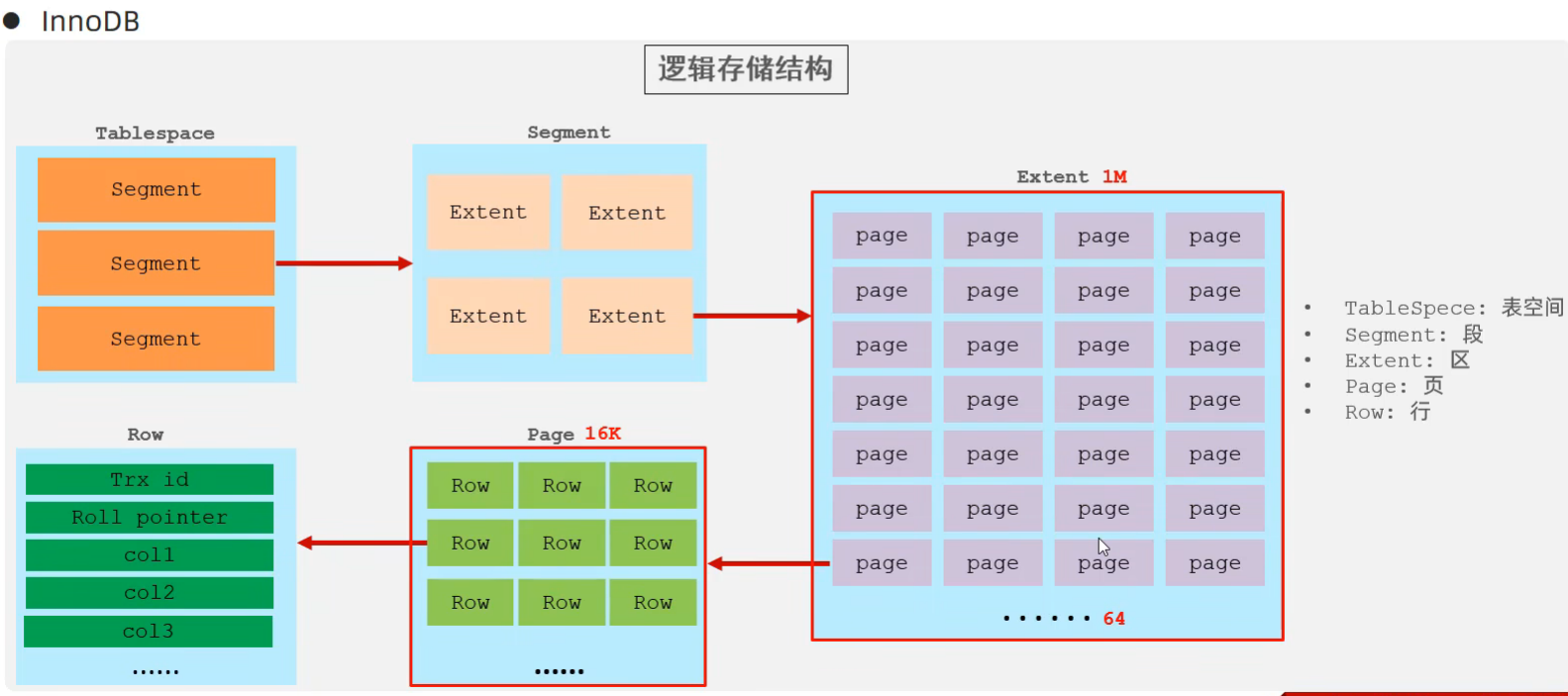
InnoDB
默认存储引擎
- 遵循ACID模型 支持事务
- 行级锁 提高并发访问性能
- 支持外键 FOREIGN KEY约束 保证数据完整性和正确性
对应文件 xxx.ibd 表空间文件{结构 数据 索引}
应用:对事务完整性比较高 在并发条件下要求数据的一致性
MyISAM
早期默认存储引擎
- 不支持事务 不支持外键
- 支持表锁 不支持行锁
- 访问速度快
xxx.MYD(数据) xxx.MYI (索引) xxx.sdi(表结构)
应用:数据操作以读取和插入为主 很少更新或删除 对事务完整性并发性瑶琴斌不是很高
Memory
存储在内存 只能作为临时表或缓存使用
- 内存存放
- hash索引(默认)
应用:临时表或缓存 对表的大小有限制
索引
帮助mysql高效获取数据的数据结构
无索引 全表扫描
索引
- 优点 调高检索效率
- 缺点 降低增删改的效率
索引结构
在存储引擎层实现 不同引擎存储不同结构
- B+Tree索引 默认
- Hash索引
- R-Tree 空间索引
- FUll-text 全文索引
B树 多路平衡查找树
度数 一个节点子节点的个数 每个节点最多存储n个指针 n-1个值
B+树
- 所有元素都会出现在叶子节点
- 叶子节点形成一个单向链表
在mysql中 优化了B+树 增加一个指向相邻叶子节点的链表指针 形成了带有顺序指针的b+树 提高区间访问性能
Hash索引
- 不支持范围查找
- 无法利用索引进行排序
- 哈希冲突 使用链表解决
- 查询效率高 只需要查询一次 通常高于B+树
索引分类
- 主键索引 primary
- 唯一索引 uniquee
- 常规索引 快速定位数据
- 全文索引 fulltext
innodb存储引擎 根据索引存储形式分为
聚焦索引: 将数据存储与索引放到了一起 索引结构的叶子节点保存了行数据 必须有而且只有一个
二级索引 :数据与索引分开存储 索引结构的叶子节点关联的是对应的主键
回表查询:先走二级索引找到主键值 然后走聚焦索引找到row
创建索引:create [unique | fulltext] index index_name on table_name (index_col_name...);
一个索引关联多个字段 称为 联合索引
查看索引: SHOW index from table_name
删除索引: DROP index index_name on table_name
性能分析
明确 sql 执行频率 增删改查所占的频率
show [session|globale] sattus like 'com_______';服务器状态信息慢查询日志
- 记录所有执行时间超过指定参数的sql语句的日志
- 慢查询日志默认没有开启 需要在配置文件配置
/etc/my.cnf添加slow_query_log=1long_query_time=2 - 查询是否开启
show variables like 'slow_query_log'; - 只会记录超过预定时间的操作才回记录
profile 详情
show profiles查看耗时都去了哪里SELECT @@have_profiling参数查看是否支持profile操作set profiling=1开启- 查看指定query_id 的sql语句各个阶段的耗时
show profile for query_id; - 查看cpu使用情况
show profile cpu for query_id
explain执行计划
- 在任意select语句之前添加关键字
explain - id 表示查询语句中执行select自居或者是操作表的顺序 id相同 按照从上往下执行 如果不同 数值越大先执行
- select_type 表示select的类型 simple(简单查询)primary(主查询 外层查询) union(union中的第二个或者后面的查询语句)subquery(select/where 之后包含了子查询)
- type 连接类型
- pssible_key 显示可能应用在这张表上的索引
- key 实际使用的索引
- key_len 索引中使用的字节数
- rows 预估值 执行查询的行数
- filtered 行数占需要读取的行数的百分比
- 在任意select语句之前添加关键字
索引使用
- 最左前缀法则
出现了联合索引 从索引的最左列开始查询 并且不跳过索引中发的列
- 索引列运算
不要在索引列上进行运算 索引将失效
- 字符串索引添加引号
否则索引将失效
- 模糊查询
尾部模糊 不会失效 头部模糊 索引失效
- or连接条件
or前条件中有索引 后面没有索引 那么涉及的索引不会用到
- 覆盖索引
查询使用了索引 并且需要返回的列 在该索引中已经全都被找到
出现 using index condition 使用了索引 但是需要回表查询
出现 using where using index 使用了索引 不需要回表查询
- 前缀索引
只将字符串的前缀简历索引 大大节约索引空间 提高索引效率
例如 create index index_name on table_name(ziduan(前缀个数));
- 单列索引 联合索引
如果存在多个查询条件 考虑针对查询字段简历索引时 建立联合索引
索引设计原则


数组比较
if (Arrays.equals(sCount, pCount)) { |







